Abstract
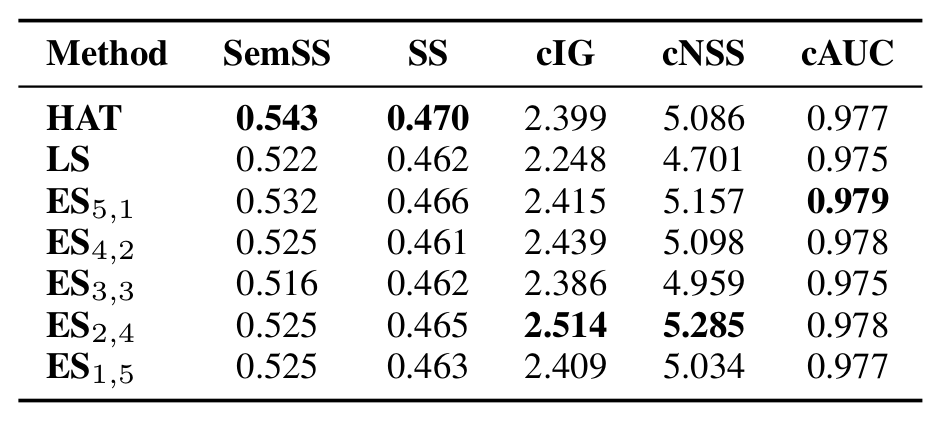
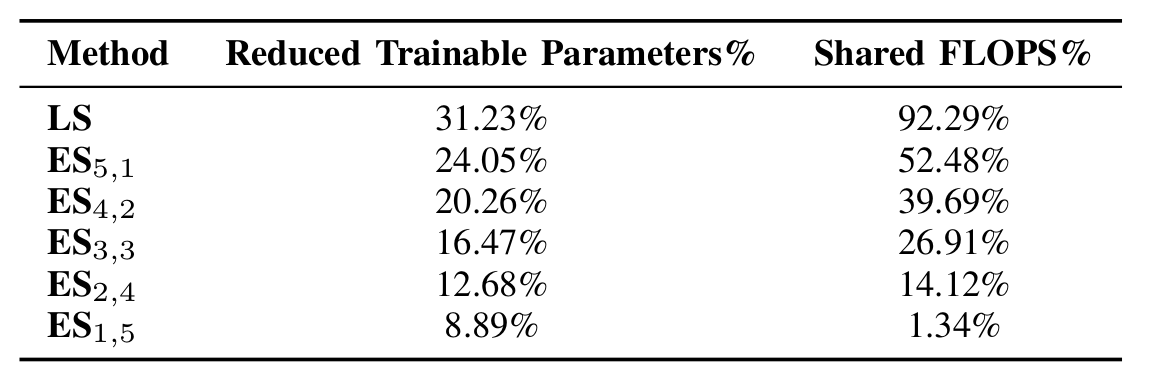
Computational human attention modeling in free-viewing and task-specific settings is often studied separately, with limited exploration of whether a common representation exists between them. This work investigates this question and proposes a neural network architecture that builds upon the Human Attention transformer (HAT) [1] to test the hypothesis. Our results demonstrate that free-viewing and visual search can efficiently share a common representation, allowing a model trained in free-viewing attention to transfer its knowledge to task-driven visual search with a performance drop of only 3.86% in the predicted fixation scanpaths, measured by the semantic sequence score (SemSS) metric which reflects the sim- ilarity between predicted and human scanpaths. This transfer reduces computational costs by 92.29% in terms of GFLOPs and 31.23% in terms of trainable parameters.
Method Overview
Our architecture, built on the Human Attention Transformer (HAT) [1], incorporates a shared represenation with the splitting stage occurring in the feature extraction module, where a number of pixel decoder layers can be shared while the other can be task-specific, allowing for adaptation to a certain task while having a shared representation.
The training scheme for the proposed architecture consists of two main stages. First, the free-viewing branch of the network is trained while keeping the weights of the visual search branch fixed. In the second stage, the shared layers are frozen, utilizing the trained weights from the free-viewing branch, and the visual search branch is then trained. This training strategy assumes that there is interplay between bottom- up and top-down visual attention and further hypothesises that as bottom-up attention is task- and object- agnostic, it can offer quite generic features within early stages of its representation, which can then be repurposed for task-driven attention.
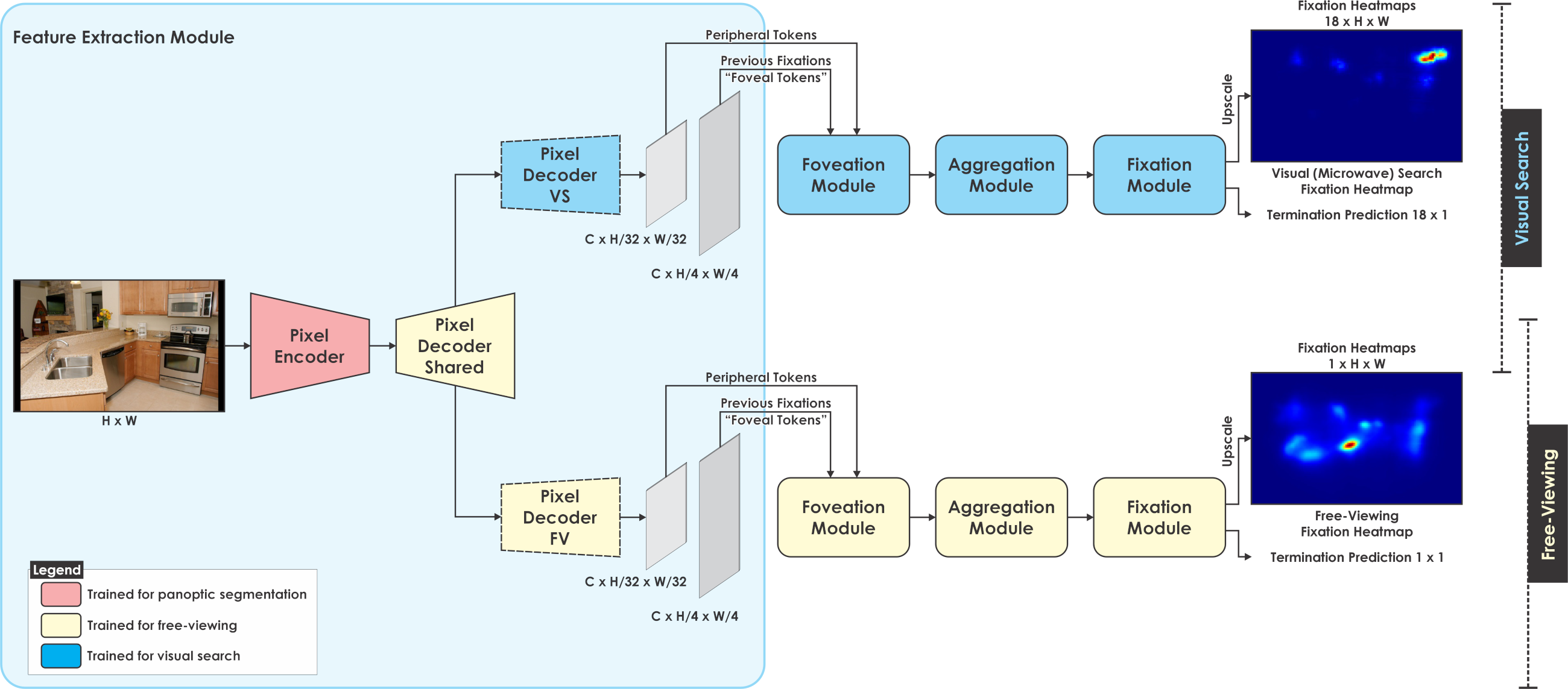
The pixel encoder is ResNet-50 [2], while the pixel decoder is MSDeformAttn [3]. The total number of transformer layers in the pixel decoder is 6. The number of shared layers can range from 1 (as in Early-Split 1-5, ES1,5) to 6 (as in Late-Split, LS), leading to 5 task-specific layers in ES1,5 and none in LS.
Results
The results indicate that a common representation exists between free-viewing and visual search, enabling reusing layers from the free-viewing task for visual search attention prediction, while achieving performance comparable with that of the HAT [1] model when trained “end-to-end” (except of its ResNet-50 based pixel encoder) on visual search. These findings lead to significant reductions in both computational cost, by 92.29% GFLOPs and model size by 31.23% trainable parameters.

BibTeX
@article{mohammed2025unified,
title={Unified Attention Modeling for Efficient Free-Viewing and Visual Search via Shared Representations},
author={Mohammed, Fatma Youssef and Alexis, Kostas},
journal={arXiv preprint arXiv:2506.02764},
year={2025}
}
References
- Z. Yang, S. Mondal, S. Ahn, R. Xue, G. Zelinsky, M. Hoai, and D. Samaras, “Unifying top-down and bottom-up scanpath prediction using transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1683–1693.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020.